




Warum präzise Umsatzprognosen für Expansion entscheidend sind
Bei der Expansion eines Unternehmens, insbesondere bei der Eröffnung einer neuen Filiale in einer neuen Region, ist die wichtigste Fragestellung, ob der Standort gut laufen wird und wie viel Umsatz dort generiert werden kann. Umsatzprognosen sind maßgebend, um die Standortwahl und die Entscheidungsfindung für eine erfolgreiche Expansion zu unterstützen. Es gibt mehrere Ansätze, die darauf abzielen, möglichst genaue und fundierte Prognosen zu erstellen.
Zwei Algorithmen des Machine Learning, die häufig zur Umsatzprognose verwendet werden, sind Random Forest und XGBoost. In dieser Fallstudie vergleichen wir die Ergebnisse dieser beiden gängigen Modelle mit den Ergebnissen, die mit dem GeoAI Modell von Targomo erzielt werden. GeoAI ist ein standortbasiertes Modell, das auf ein besseres Verständnis von Standortfaktoren und deren konkrete Bewertung trainiert wird.
Grundlage für diese Fallstudie sind die öffentlich zugänglichen Daten über den Verkauf von Spirituosen im US-Bundesstaat Iowa. Für eine mögliche Prognose wählten wir die Marke Hy-Vee aus und behandelten die Spirituosenverkäufe anderer Marken als Daten von Wettbewerbern.
Wer ist Hy-Vee? Das Unternehmen ist eine Supermarktkette, die hauptsächlich im Mittleren Westen und im Süden der USA ansässig ist. Der Hauptsitz des Unternehmens befindet sich in West Des Moines, Iowa. Hy-Vee hat über 285 Standorte in 8 US-Bundesstaaten, neben Iowa zum Beispiel auch in Illinois und Missouri.
Drei Ansätze im Vergleich: Random Forest, XGBoost und GeoAI
Die drei Methoden Random Forest, XGBoost und GeoAI von Targomo wurden für die Modellierung berücksichtigt. Random Forest und XGBoost sind beliebte universal einsetzbare Machine Learning Algorithmen. Vor allem XGBoost findet man oft auf den Podesten von Machine Learning Wettbewerben in verschiedensten Anwendungsbereichen wieder. Die Algorithmen sind dank existierender Python/R-Pakete leicht zugänglich und ermöglichen es, schnell erste Ergebnisse zu erhalten. Es gibt jedoch auch bekannte Nachteile: Mögliche Probleme mit Overfitting, also der Überanpassung, und auch häufig eine schwierige Interpretierbarkeit der Ergebnisdaten. Vor allem Overfitting ist bei der Umsatzmodellierung ein großes Problem, denn Trainingsdaten (also das eigene Filialnetz) umfassen bestenfalls einige Hundert Datensätze. Die beste Performance liefern Random Forest und XGBoost bei der Arbeit mit Daten die Millionen Datenpunkte umfassen.
GeoAI ist ein standortbezogenes Verfahren. Die Grundlagen des Modells wurden im Rahmen eines Forschungsprojektes von Targomo in Kooperation mit dem Hasso-Plattner-Institut und dem Deutschen Zentrum für Luft- und Raumfahrt entwickelt.
So funktioniert GeoAI: Gravitationsmodell & Attraction Strength
Ein wichtiger Bestandteil von GeoAI ist ein Gravitationsmodell. Es folgt der Idee des Newtonschen Gravitationsgesetzes und wendet das Konzept auf Marktmodelle an. Nach dem Newtonschen Gravitationsgesetz führen hohe Massen (Attraktivität in Marktmodellen) und eine geringe Entfernung zu einer starken Anziehung. Die Anziehungskraft wird in unserem Beispiel anhand von Shop-Merkmalen und Umgebungsmerkmalen gemessen. Bei diesen Merkmalen kann es sich um die Größe des Geschäftes, Verfügbarkeit von Parkplätzen, Beschaffenheit des Produktsortimentes oder um Standortfaktoren wie komplementäre Geschäfte, Konkurrenten oder andere Points of Interest in der Nähe handeln.
In unserem Modell werden diese Faktoren in der Attraction Strength zusammengefasst. Die Entfernung wird auf der Grundlage der Reisezeit berechnet, wobei die Einzugsgebiete durch die Reisezeit und den jeweiligen Reisemodus (Auto, Fahrrad, öffentlicher Nahverkehr und zu Fuß) definiert werden. Eine reisezeitbasierte Berechnung des Einzugsgebietes bietet eine präzisere und realistischere Einschätzung als naivere entfernungsbasierte Berechnung.
Fallstudie „GeoAI für Umsatzprognosen im Einzelhandel“ – Zusammenfassung
Schritt 1: Datenerhebung
Zunächst musste das Data-Team von Targomo die Daten aus verschiedenen Quellen zusammentragen, um die allgemeine Nachfrage und Attraktivität der verschiedenen Geschäftsstandorte zu berechnen:
- Öffentlich zugängliche Daten über Spirituosenkäufe: Die Daten umfassen Geschäfte mit Iowa-Lizenzen der Klasse „E“ wie Lebensmittelgeschäfte, Spirituosenläden und Convenience Stores. Der Datensatz erfasst Spirituosenkäufe auf Shop-Ebene von 2012 bis heute und enthält den Shopnamen, die Shopnummer, die Adresse und die Koordinaten des Ladengeschäftes, sowie das Datum der Bestellung, die bestellten Artikel, die Verkaufswerte und die Produktkategorien. Der Verkaufswert wird berechnet, indem die Anzahl der verkauften Flaschen mit dem staatlichen Einzelhandelspreis multipliziert wird. Dieser Wert ist der Zielwert für den Beispiel-Case.
- Soziodemografische Daten: Altersgruppe, Einkommen, Beruf, Familienstruktur, Verkehrsmittel für den Arbeitsweg und mehr.
- Mobilitätsdaten: Bewegungsdaten in Form von Fußgängerverkehr geben an, wie viele Personen sich in einem bestimmten Zeitraum an einem Ort aufhalten.
- Daten zur Attraktivität von Geschäften: Wenn Kunden die Geschäfte und Shop-Möglichkeiten innerhalb eines Einzugsgebiets als unterschiedlich attraktiv wahrnehmen, kann sich dies auf die Wahl des Geschäfts auswirken, in dem sie bevorzugt einkaufen. Um die Attraktivität in der Modellierung zu berücksichtigen, haben wir direktes Kundenfeedback in Form von Google-Bewertungen mit einbezogen. Dabei wurden die durchschnittlichen Google-Bewertungen und die Anzahl der Bewertungen verwendet. Darüber hinaus wurden auch die Öffnungszeiten (über ein Jahr betrachtet als Anzahl der Gesamtstunden) berücksichtigt.
- Daten der Wettbewerber: Da die öffentlich zugänglichen Daten alle Spirituosenverkäufe abdeckten, wurden die Daten anderer Geschäfte ebenfalls verwendet und als Wettbewerber neben Hy-Vee behandelt.
- Welche Daten fehlten? Die Größe der Filiale und die Größe der Verkaufsfläche haben in der Regel einen erheblichen Einfluss auf den Umsatz einer Filiale und sollten immer in der Modellierung für die Prognose einbezogen werden. In diesem Fall waren die Daten nicht verfügbar und konnten somit nicht berücksichtigt werden.
Schritt 2: Datenbereinigung – als Grundlage für die fundierte Modellierung
Bei der Datenbereinigung werden ungenaue, unvollständige und doppelte Datensätze identifiziert und anschließend korrigiert oder entfernt.
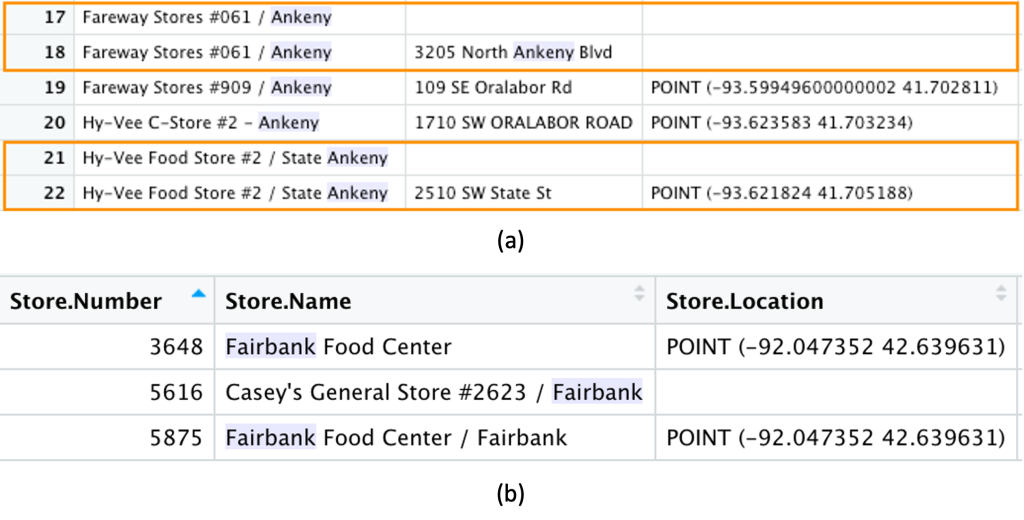
- Erkennung ungenauer, unvollständiger und doppelter Datensätze: In vielen Datensätzen fehlten Adressen und Koordinaten (Abbildung a, hervorgehoben in orangefarbenen Kästchen), sodass wir die fehlenden Daten mit bekannten Einträgen oder aus Geokodierungsergebnissen ergänzten. Außerdem kam es vor, dass dieselben Geschäfte doppelt mit verschiedenen Geschäftsnummern auftauchten (Abbildung b, Geschäftsnummer 3648 und 5875). Um diese Duplikate zu identifizieren, berechneten wir eine Abstandsmatrix zwischen allen Geschäften. Wenn der Abstand zwischen zwei Geschäften weniger als 50 m betrug, wurde ein Cluster gebildet. Anschließend wurden alle Geschäfte in diesem Cluster manuell dahingehend überprüft, ob es sich um dasselbe Geschäft handelt oder nicht.
- Identifizierung von Ausreißern und Behandlung fehlender Werte: Nach Korrektur der ungenauen Datensätze wurden die monatlichen Umsätze von 2019 für jedes Geschäft aufsummiert und die Anzahl der einzelnen Spirituosenkategorien und der gekauften Spirituosenartikel gezählt. Wenn ein Geschäft nicht für jeden Monat Umsatzdaten gemeldet hatte, wurde es aus dem Trainingsdatensatz entfernt. Es wurde jedoch in der Analyse wie ein Konkurrent behandelt, d. h. ein Geschäft, das potenziell Kunden anzieht, dessen Umsätze jedoch nicht bekannt sind.
Darüber hinaus wurden Geschäfte mit extrem hohen oder niedrigen Jahresumsätzen sorgfältig überprüft, wobei festgestellt wurde, dass es sich bei den meisten um Großhandelsunternehmen handelte. Da diese Geschäfte andere Kundengruppen – nämlich andere Geschäfte – ansprechen, wurden diese Ausreißer aus dem Datensatz entfernt. Kasinos, Hotels, Gasthöfe und Brennereien wurden ebenfalls entfernt.
Schritt 3: Training des Prognosemodells mit Daten
Der GeoAI Algorithmus lernt auf Basis der Standortdaten und der Umsätze, welche Datenzusammensetzung die Leistung der Hy-Vee-Filialen am besten repräsentiert.
Das Training besteht aus zwei Hauptkomponenten:
- Key Driver Analysis: Wir ermitteln die Faktoren der Attraction Strength. Das sind die Standortvariablen, die einen Standort für die Zielgruppe attraktiv machen und Kunden zum Standort locken.
- Validierung und Feinabstimmung: In unzähligen Iterationen validieren wir das Modell anhand zusätzlicher Daten zum Geschäftsstandort und nehmen eine Feinabstimmung vor.
Ergebnisse: GeoAI ist genauer und robuster
Es gibt zwei relevante Werte, die während des Lernprozesses gemessen werden und die Prediction Quality anzeigen, also die Qualität der Vorhersage: Der Trainingsfehler (training error) und der Testfehler (testing error).
- Der Trainingsfehler misst die Fähigkeit eines Modells, genaue Vorhersagen für Daten zu treffen, auf denen das Modell trainiert wurde. Er hilft uns, das Potenzial eines Modells einzuschätzen und zeigt, ob wir uns bei der Optimierung in eine sinnvolle Richtung bewegen.
- Der Testfehler wird anhand von Prognosen für einen Datensatz oder mehrere Datensätze gemessen, die das Modell noch nicht gesehen hat. Auf diese Weise lässt sich feststellen, wie gut das Modell Vorhersagen für neue Standorte treffen kann, die nicht im Trainingsset enthalten waren. Dies ist wichtig, um Overfitting zu erkennen und zu vermeiden.
Bei den Prognose-Ergebnissen kann der Testfehler als aussagekräftiger angesehen werden, da er uns eine Vorstellung davon vermittelt, wie gut das Modell bei neuen, ungesehenen Daten – wie der Adresse eines potenziellen neuen Standorts für eine Geschäftseröffnung – abschneiden wird. Ein niedriger Trainingsfehler ist eine Voraussetzung, aber kein ausreichender Indikator für ein erfolgreiches Modell.
Bei unseren Projekten zur Umsatzvorhersage durchlaufen wir während des Modelltrainings normalerweise zwei Phasen:
- In der ersten Phase wollen wir den Trainingsfehler minimieren, um zu beweisen, dass das Modell aussagekräftig/komplex genug ist, um Vorhersagen für den spezifischen Anwendungsfall zu machen und dass wir alle Daten über relevante Erfolgsfaktoren beisammenhaben.
- In der zweiten Phase wollen wir das Modell verallgemeinern, so dass es für neue, unbekannte Orte funktioniert. Wir wollen also den Testfehler minimieren, oft durch eine weitere Reduzierung der Modellkomplexität.
Ergebnisse: Dies sind die Standortvariablen, die den Verkauf von Spirituosen beeinflussen
Die Tabelle vergleicht die Modellgenauigkeit (model accuracy) und die erkannten Erfolgsfaktoren (success driver) von drei Modellen zur Prognose des Alkoholverkaufs in Hy-Vee-Filialen. Der Trainingsfehler des GeoAI Modells liegt bei 16 % und der Testfehler bei 19,8 %, während die Testfehler des Random Forest-Modells und des XGBoost-Modells trotz ausgiebigem Hypertuning 38,1 % bzw. 30 % betragen. Im Vergleich zu den beiden häufig verwendeten Modellen liefert GeoAI somit die höchste Genauigkeit.
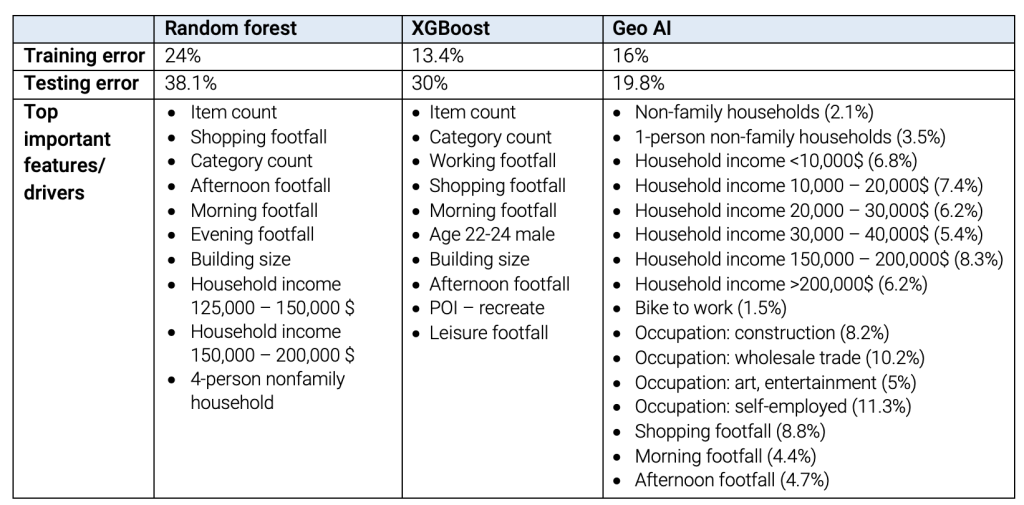
Die identifizierten Attribute in den Random-Forest- und XGBoost-Modellen sind eher begrenzt und beschränken sich auf die Anzahl der Artikel, die Anzahl der Besucher und ein oder zwei weitere soziodemografische Merkmale. Die Hinzunahme zusätzlicher Attribute führt bei den Modellen zu Overfitting.
Im Gegensatz dazu besteht das GeoAI Modell aus einer breiten Palette von Attributen, zu denen unter anderem Shop-Merkmale (Anzahl der Artikel, Art des Ladens), die Umgebung (Passantenfrequenz am Standort) und soziodemografische Merkmale potenzieller Kunden gehören. Die Anzahl der Artikel, die die Vielfalt der im Geschäft angebotenen Spirituosen angibt, der Ladentyp und die Passantenfrequenz in der näheren Umgebung werden zur Messung der Attraktivität des Geschäfts im Gravitationsmodell verwendet.
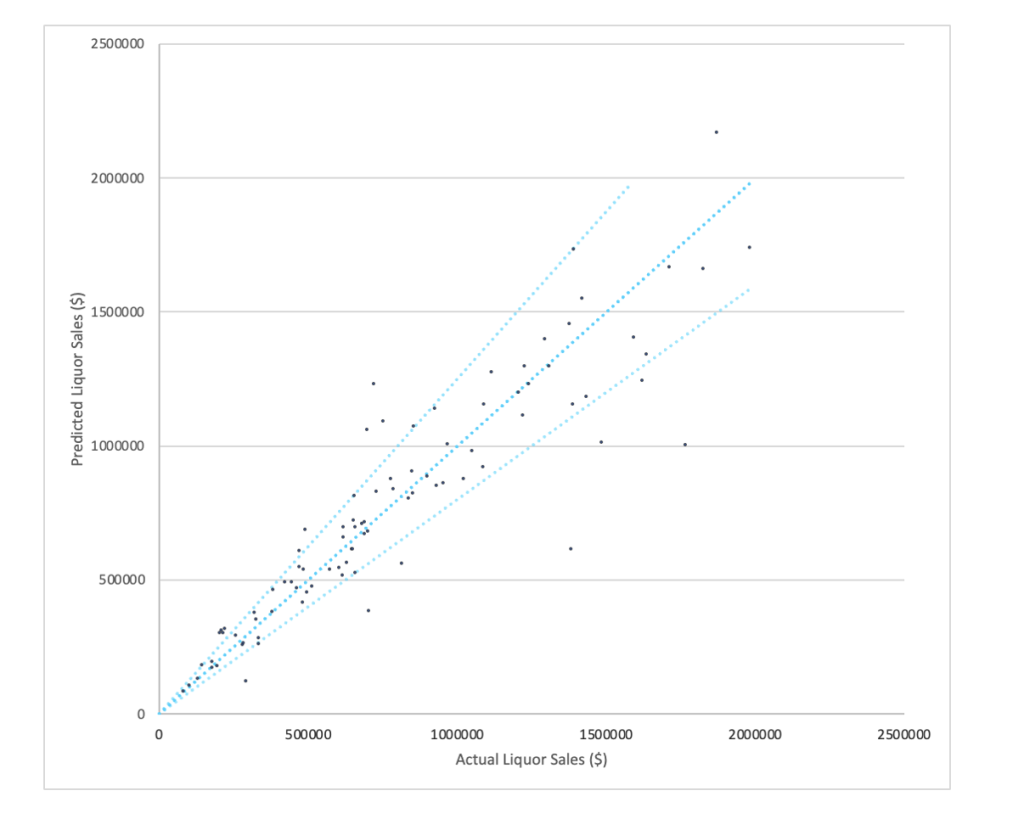
Der Scatter Plot vom GeoAI Output: Die X-Achse weist den tatsächlichen Umsatz an Spirituosen aus, die Y-Achse beschreibt den prognostizierten Umsatz an Spirituosen. Die Punkte sind entlang der diagonalen Linie gut verteilt, ein Indikator für eine gute Prognoseleistung der GeoAI!
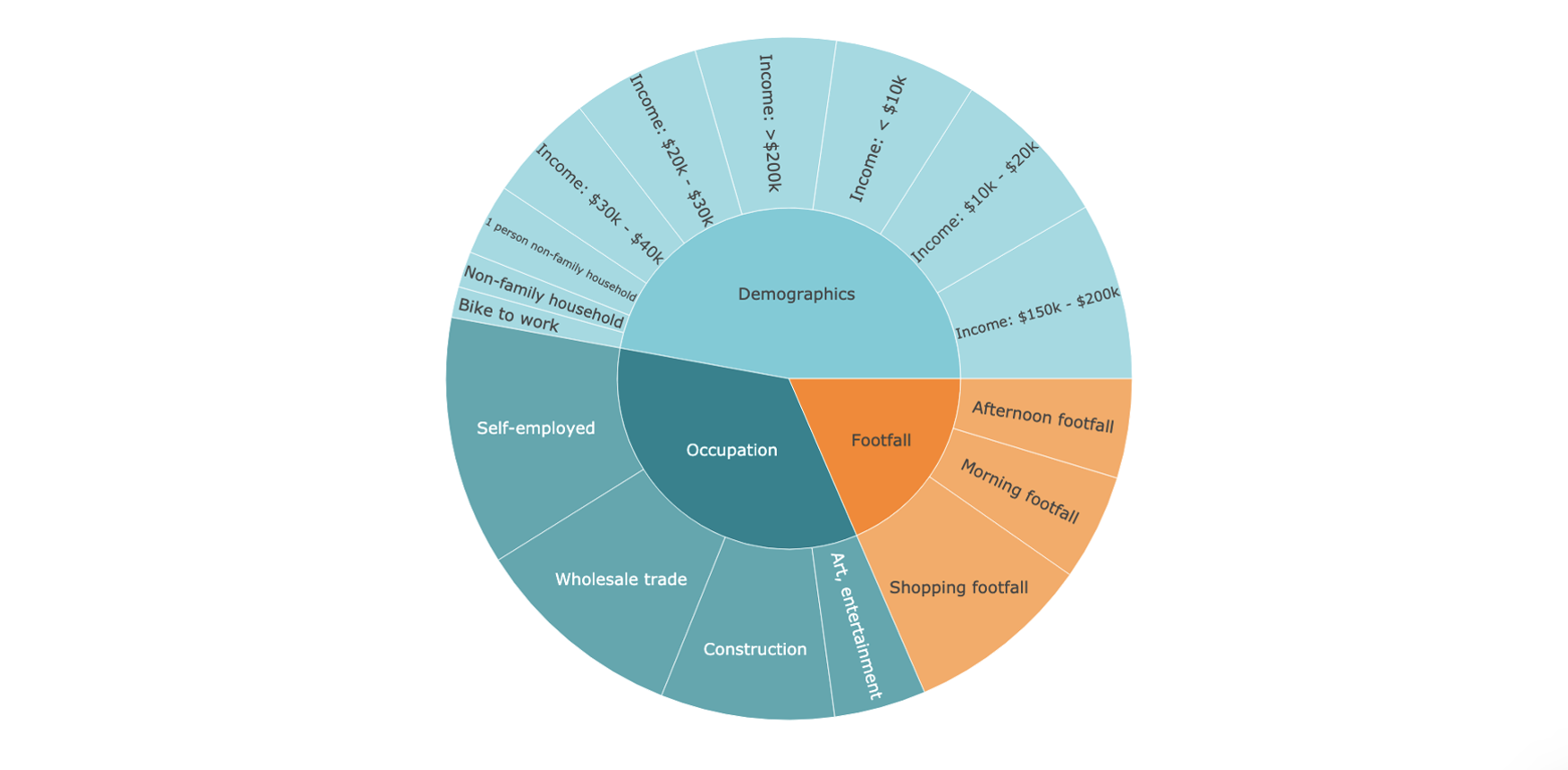
Visualisierung des GeoAI Erfolgstreiberprofils
Das Attribut “Einkommen” ist ein wichtiger Faktor für den Verkauf von Spirituosen in Hy-Vee-Märkten. 25,8 % der Verkäufe stammen aus Haushalten mit einem Einkommen von weniger als 40.000 $, und 14,5 % aus Haushalten mit einem Einkommen von mehr als 150.000 $. Viele Studien haben ergeben, dass Personen mit niedrigem Einkommen ein höheres Risiko für schweren und riskanten Alkoholkonsum haben, und dass ein höheres Einkommen mit einer höheren Häufigkeit von leichtem Alkoholkonsum verbunden ist.
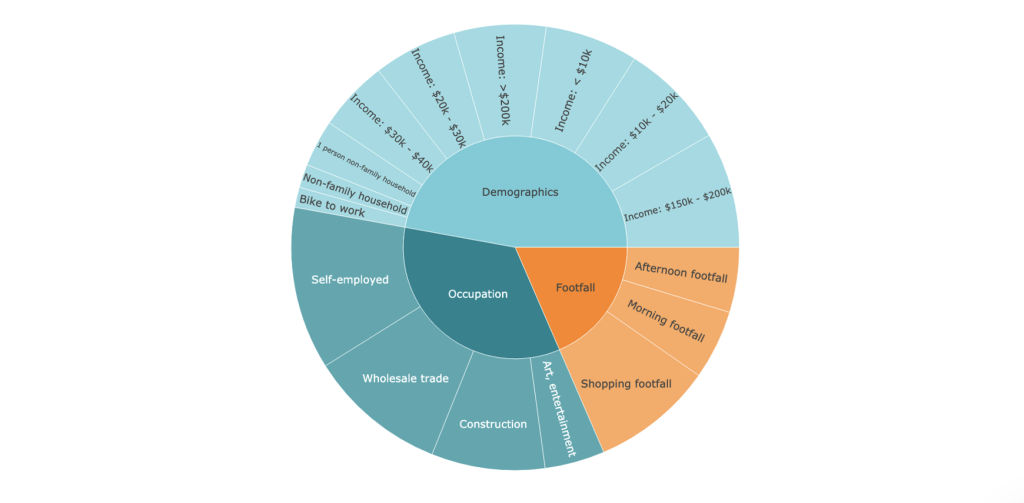
Neben dem Einkommen hat auch die Zugehörigkeit zu bestimmten Berufsgruppen einen positiven Einfluss auf den Verkauf von Spirituosen in Hy-Vee-Märkten in Iowa. Die Ergebnisse zeigen, dass es sich verkaufsfördernd auswirkt, wenn viele Personen aus dem Baugewerbe, dem Großhandel, der Kunstindustrie sowie Selbstständige in der Nähe zu verorten sind. Laut Statista sind die Top 5 Berufsgruppen mit hohem Alkoholkonsum (15 oder mehr alkoholische Getränke pro Woche) in den USA 2016: Baugewerbe/Bergbau, Installation/Reparatur, Landwirtschaft/Fischerei/ Forstwirtschaft, Fertigung/Produktion, sowie Geschäftsinhaber (business owner). Unter diesen Berufen ist das Baugewerbe einer der in dem Modell ermittelten Treiber.
Die anderen ermittelten Berufe korrelieren ebenfalls stark mit den durch die GeoAI ermittelten Berufsgruppen, so sind beispielsweise die Berufskategorien Installation/Reparatur, Landwirtschaft/Fischerei/Forstwirtschaft und Fertigung/Produktion häufig als Selbständige und als Geschäftsinhaber ausgewiesen. Wir können also sehen, dass viele von GeoAI identifizierte Faktoren mit empirischen Forschungsergebnissen übereinstimmen.
Dynamische Analyse für Hy-Vee mit GeoAI
Integriert in die Plattform TargomoLOOP, liefert das GeoAI Modell schnelle Prognoseergebnisse für jede mögliche Adresse.
Insights aus dem Modell: Was Umsatz wirklich treibt
Erkenntnis #1 Eine gute Einschätzung der Attraction Strength ist entscheidend.
Die Attraction Strength gibt an, wie attraktiv “unsere” Geschäfte sind und wie attraktiv/konkurrenzfähig sich die jeweiligen Wettbewerber darstellen. Eine gute Schätzung der “Anziehungskraft” ermöglicht eine bessere Einschätzung der Marktgröße und der potenziellen Kunden und erlaubt somit eine genauere Prognose der Einnahmen. Bei der Schätzung der Anziehungskraft sind Informationen über das Geschäft von entscheidender Bedeutung, z. B. die Größe des Geschäfts, die Verkaufsfläche und die Öffnungszeiten. In dieser Fallstudie reichen die uns zur Verfügung stehenden Informationen aufgrund der Beschränkung öffentlicher Daten nicht aus, um ein vollständiges Bild der Attraktivität des Geschäfts zu zeichnen, da Informationen zu Ladenfläche der Geschäftsstandorte fehlen. Um diese Einschränkung zu umgehen, wurde stattdessen die Vielfalt der Spirituosenprodukte als Shop-Merkmal verwendet.
Erkenntnis #2 Ein attraktiver Ladenstandort wird durch sein geschäftliches Umfeld UND den Zugang zu seiner Zielgruppe definiert.
Bei der Auswahl eines neuen Standorts für die Eröffnung eines Geschäfts sind umliegende Unternehmen von entscheidender Bedeutung. Welche Produkte/Dienstleistungen bieten sie an? Wie ist die Atmosphäre? Stehen sie im Wettbewerb oder ergänzen sie das eigene Geschäft? Bei der Entscheidungsfindung muss jedoch auch die geografische Verteilung der demografischen Zielgruppen berücksichtigt werden. Es spielt keine Rolle, wie gut ein Standort für ein potenzielles Geschäft geeignet ist, wenn die Zielkundengruppe nicht in der Lage oder nicht bereit ist, dorthin zu reisen.
Bei der Verwendung von Random-Forest- und XGBoost-Modellen ist es schwer zu kontrollieren, welche Variablen im Entscheidungsbaum verwendet werden. In dieser Fallstudie konzentrierten sich diese beiden Modelle hauptsächlich auf die nähere Umgebung und berücksichtigten den Zugang zu den demografischen Zielgruppen nur in geringem Maße. Das GeoAI Modell legte einen größeren Schwerpunkt auf die Demografie und berücksichtigte eine breitere Palette von demografischen und umweltbezogenen Faktoren.
Erkenntnis #3 Insiderwissen kann bei der Analyse von Schlüsselfaktoren ein zweischneidiges Schwert sein.
Bei der Auswahl der Variablen in der Analyse der Erfolgsfaktoren kann Insiderwissen Aufschluss darüber geben, welche Schlüsseltreiber aufgrund von Erfahrungen oder vorhandener Literatur zu erwarten sind. Wenn man sich jedoch zu sehr auf Expertenwissen verlässt und zu Beginn Daten ausschließt und ignoriert, die man nicht für relevant hält, kann man in eine Falle tappen.
Wenn man stattdessen das Modell und die Daten sprechen lässt, kann man neue, unerwartete Erkenntnisse gewinnen. Oft stellen wir fest, dass Variablen, die wir für wichtig hielten, wenig oder gar keine Bedeutung haben, und umgekehrt. Es ist wichtig solche Fälle zu untersuchen, die Ursachen herauszufinden und Erklärungsmöglichkeiten zu suchen. Idealerweise sollten unsere Annahmen das Modell nicht beeinträchtigen.
Der Mechanismus zur Auswahl von Merkmalen in GeoAI sorgt dafür, dass das Modell selbst bei einer großen Anzahl von Merkmalen als Eingabe nicht unter Overfitting leidet. Dadurch kann eine Vielzahl von möglichen Einflussfaktoren getestet und vom Modell auf die relevanten reduziert werden.
Fazit: GeoAI als Werkzeug für präzisere Site-Selection
Diese Fallstudie testet und vergleicht die Leistung von drei Modellen, Random Forest, XGBoost und GeoAI als Methoden zur Umsatzprognose unter Verwendung von Spirituosenverkaufsdaten aus Iowa, USA. GeoAI zeigt unter allen drei Modellen die beste Leistung, da es am wenigsten overfittet, den niedrigsten Testfehler aufweist und die relevanten Einflussfaktoren im Modell umfassender abgebildet werden.
Im Vergleich zu den Modellen Random Forest und XGBoost berücksichtigt GeoAI stärker die Shop-Merkmale, die Umgebung des Ladens, die lokale demografische Struktur und die Mobilitätsdaten, wodurch das Modell zuverlässiger ist. Darüber hinaus bietet GeoAI von Targomo als ortsbezogenes Modell ein besseres Verständnis und eine generauere Bewertung der Standortfaktoren. Es ist möglich, die Prognosen des Modells im Detail nachzuvollziehen und die relevanten Umsatztreiber für jeden individuellen Geschäftsstandort auszuwerten.
GeoAI kann in verschiedenen Branchen eingesetzt werden, unter anderem im Einzelhandel und bei der Standortplanung von gastronomischen Betrieben. Möchten Sie mehr über Targomo’s Prognosen mit GeoAI für Einzelhändler und Gastronomiebetriebe erfahren und dynamische Analysen in Action sehen?
GeoAI wurde von Targomo’s Data Science Team mit dem Ziel entwickelt zu evaluieren, welche Standortfaktoren den Geschäftserfolg von Marken und Unternehmen beeinflussen und in welchem Maße diese zum Umsatz beitragen.
Vielleicht interessiert Sie auch